

Most Frequently Asked Interview Questions on Machine Learning in 2024
This basic framework and the algorithms of ML are crucial areas where interviewers assess a candidate’s competency. So, to help you use your talents in an interview, we’ve created a detailed article with interview questions and answers.
Top Machine Learning Interview Questions:
Here is a list of common interview questions:
What is Machine Learning?
Machine Learning is a discipline of computer science that works with system programming to learn and improve automatically over time. For example, robots are programmed to do tasks depending on data collected via sensors. It learns programs from data automatically.
What are the types of Machine Learning?
There are three different types of ML:
- Supervised Learning: In this type of ML, the model makes judgments or predictions based on labeled or historical data. Labeled data is data sets that include labels or tags.
- Unsupervised Learning: This type of ML does not have labeled data. A model can detect anomalies, correlations, and trends in the input data.
- Reinforcement Learning: In reinforcement learning, a model can learn based on the rewards it received from previous behaviors.

Machine Learning Course Curriculum
What is the difference between Deep Learning and Machine Learning?
Deep Learning
Machine Learning
Deep Learning is a type of ML that combines the artificial neural network with the recurrent neural network.
ML is a category or application of AI that enables the system to improve and learn from experience without being designed to do so.
The algorithms are constructed in the same way as machine learning is. However, there are many more tiers of algorithms. All of the algorithm’s networks are referred to together as the artificial neural network.
ML involves creating computer software that reads data and utilizes it to learn from itself.
Difference between Deep Learning and Machine Learning
Explain Machine Learning’s ‘Overfitting’!
Statistical models overfit when they represent random error or noise instead of underlying relationships. Overfitting is common when a model is overly complicated due to having too many parameters in relation to the amount of training data types. The model has poor performance due to overfitting.
Can ‘Overfitting’ be avoided?
Overfitting may be prevented by employing a large amount of data; overfitting occurs comparatively when you have a small dataset and try to learn from it. However, if you have a little database and are obliged to create a model based on it, then employ a cross-validation method. This method divides the dataset into two sections: testing and training. Test datasets are used to test models, whereas training datasets are used to develop models from data.
What are the ‘Test set’ and ‘Training set’?
A collection of data known as the ‘Training Set’ is utilized in different fields of information science, such as ML to uncover the possible predictive link.
In contrast, the test set is used to assess the accuracy of the learner’s hypotheses and is a set of instances withheld from the learner. Training and test sets are separate.
What are the five most popular Machine Learning algorithms?
Here are the top five ML algorithms:
- Neural Networks,
- Support Vector Machines
- Nearest Neighbor,
- Decision Trees,
- Probabilistic Networks

Machine Learning Batch Details
Explain the difference between Machine Learning and Artificial Learning!
Machine Learning is the process of designing and creating algorithms based on empirical data. In addition to machine learning, artificial learning encompasses knowledge representation, planning, natural language processing (NLP), robotics, and other areas.
What is Machine Learning’s Model Selection?
Model selection refers to the process of picking models from among various mathematical models that are used to represent the same data collection in Machine Learning. Model selection is used in statistics, machine learning, and data mining.
What are Classification and Regression in ML?
Classification – It is the procedure of locating or creating a model or function that assists in categorizing data into various categorical classes, i.e., discrete values. The classification process involves predicting labels for data based on specific input factors and then categorizing it accordingly.
Regression is the process of determining a model or function for separating data into continuous real values rather than classes or discrete values. Based on previous data, it may also determine dispersion movement. Since a regression predictive model predicts a variable, its accuracy must be expressed as an error in those predictions.
Explain Dimensionality Reduction in ML!
In addition to providing more accurate findings, more data can also affect machine learning algorithms’ performance (for example, overfitting) and make the visualization of datasets more challenging. Dimensionality reduction is used when a given dataset’s number of attributes or dimensions is too great. Data inputs are minimized to a reasonable amount while keeping the dataset’s integrity as much as possible.
What is Batch Statistical Learning?
The machine learning algorithm in batch learning only adjusts its parameters after absorbing batches of fresh data. Because models are trained using big batches of collected data, additional time and resources, such as CPU, storage capacity, and disk input/output, are required.
What are Recall and Precision?
- Precision: It is sometimes referred to as a positive predicted value. This depends more on the predictions. It is a measure of how many accurate positives the model promises against how many positives it really claims.
- Recall: It is referred to as a true positive rate. The number of positives claimed by the model compared to the total number of positives available in the data.
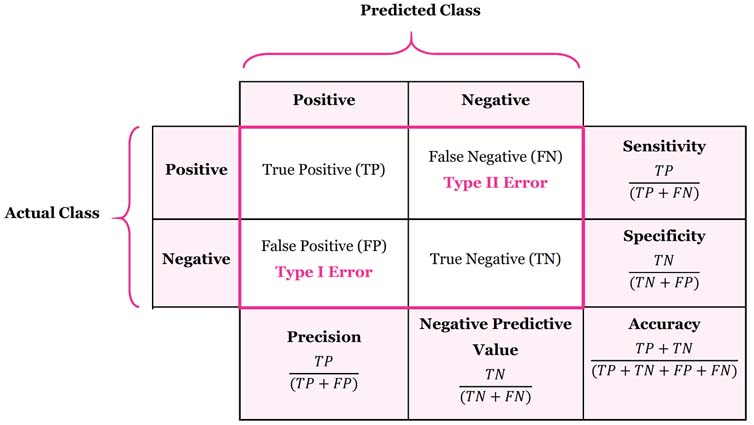
What is Confusion Matrix in ML?
A confusion matrix, also known as an error matrix, is a table that summarises the performance of a classification method.

Confusion Matrix or Error Matrix
Explain Bayes’ Theorem in Machine Learning!
In Bayes’ theorem, the likelihood of any event occurring is calculated using past information. A true positive rate is calculated by dividing the true positive rate of a sample condition by the sum of the true positive rate of the whole population.
Bayesian belief networks and Bayesian optimization are the most important applications of Bayes’ theorem in Machine Learning. This theorem is also the foundation for Machine Learning, which uses the Naive Bayes classifier.

Bayes Theorem
Conclusion:
The questions given above are the fundamentals of Machine Learning. Because machine learning is snowballing, new concepts will arise. So, to stay current, join communities, attend conferences, and read research papers. This will allow you to pass any ML interview. Courses at Training Basket will help you grow and crack your Dream Job!
.png)







{kind=link}